



Implementing a Custom dbt Incremental Strategy with Delta Lake Change Data Feed
As data volumes grow, scanning an entire dataset during every ETL run quickly becomes a bottleneck for both time and compute resources. To build more efficient and scalable pipelines, adopting incremental processing is a natural next step.
While incremental pipelines are straightforward when managing inserts and updates, handling upstream hard deletes introduces significant complexity.
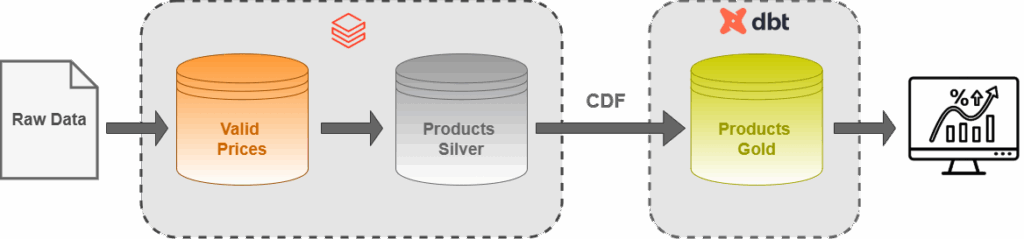
This article details how to overcome standard dbt (Data Build Tool) architectural limitations by designing a custom incremental strategy. This solution directly consumes Change Data Feed (CDF) log versions, from the Silver layer, to natively process inserts, updates, and deletes, without introducing operational metadata columns to the final Gold layer production schema.
The Challenge: Why Standard dbt Incremental Strategies Fall Short
While data processing in the Bronze and Silver layers is handled via Apache Spark in Databricks, we chose dbt to manage the Gold layer transformations. To optimize processing efficiency, we enabled Change Data Feed (CDF) on our Silver Delta tables to capture row-level changes between pipeline executions.
ALTER TABLE silver.products
SET TBLPROPERTIES (delta.enableChangeDataFeed = true);
When configuring dbt to process these micro-changes incrementally, we encountered two primary technical roadblocks:
- The Inability to Process Deletions Natively: Standard dbt incremental merge strategies rely on a unique_key matching algorithm to insert new records or update existing ones. If a record is deleted in the source table, the native merge statement lacks the contextual awareness to execute a corresponding DELETE target operation.
- The Metadata Schema Contamination: An initial workaround involved passing the operational _change_type column directly into the Gold layer and utilizing a dbt post_hook to execute a secondary cleanup DELETE query. While functionally viable, this approach compromised data modeling principles by forcing a production-ready Gold schema to house transient, system-level metadata columns. Also _commit_version column was used as vital information for chronological sequencing and deduplication of consecutive changes to the same record.
Our objective was to design an enterprise-grade solution that processes CDF changes holistically during the atomic merge phase, keeping the downstream Gold schema completely pristine.
The Solution: A Custom cdf_merge Incremental Engine
To achieve an atomic merge capable of handling deletions, we abandoned default merge strategy and utilized extended dbt’s core capability by writing a custom incremental strategy. This engine interrogates the source Delta table’s transaction logs via the table_changes() function and tracks state explicitly using Delta table properties instead of external audit logs.
Step-by-Step Architecture Implementation
1. State Management via Table Metadata Properties
To run an incremental pipeline without depending on unstable timestamp logic, the engine must precisely track the last processed Delta version. Instead of keeping the information about the version as an additional metadata column we decided to migrate it to Gold table’s metadata using
ALTER TABLE SET TBLPROPERTIES.
Following helper macros were implemented for this purpose:
{% macro get_cdf_version(relation) %}
{% set v_query %} SHOW TBLPROPERTIES {{ relation }} ('last_processed_silver_version') {% endset %}
{% set result = run_query(v_query) if execute %}
{% if execute and result and result.rows | length > 0 %}
{{ return(result.columns[1][0] | int) }}
{% endif %}
{% endmacro %}
{% macro set_cdf_version(target_relation, source_relation) %}
{% set silver_v_query %}
SELECT MAX(version) FROM (DESCRIBE HISTORY {{ source_relation }})
{% endset %}
{% set silver_v = run_query(silver_v_query).columns[0][0] if execute %}
ALTER TABLE {{ target_relation }}
SET TBLPROPERTIES (
'last_processed_silver_version' = '{{ silver_v }}'
);
{% endmacro %}2. Overriding the Merge Behavior: get_incremental_cdf_merge_sql
Next, we define the custom macro that maps the standard dbt staging lifecycle to our specific CDF requirement. By referencing the _change_type attribute inside a temporary staging view, the macro can explicitly execute DELETE, UPDATE, or INSERT operations in a single database transaction.
{% macro get_incremental_cdf_merge_sql(arg_dict) %}
{% set target = arg_dict["target_relation"] %}
{% set temp = arg_dict["temp_relation"] %}
{% set unique_key = arg_dict["unique_key"] %}
{% set dest_columns = adapter.get_columns_in_relation(target) %}
{% set dest_cols_csv = dest_columns | map(attribute='name') | join(', ') %}
MERGE INTO {{ target }} t
USING {{ temp }} s
ON t.{{ unique_key }} = s.{{ unique_key }}
-- Process Upstream Deletions
WHEN MATCHED AND s._change_type = 'delete' THEN DELETE
-- Process Upstream Updates
WHEN MATCHED AND s._change_type = 'update_postimage' THEN
UPDATE SET
{% for col in dest_columns %}
t.{{ col.name }} = s.{{ col.name }}{% if not loop.last %}, {% endif %}
{% endfor %}
-- Process Upstream Insertions
WHEN NOT MATCHED AND s._change_type = 'insert' THEN
INSERT ({{ dest_cols_csv }})
VALUES(
{% for col in dest_columns %}
s.{{ col.name }}{% if not loop.last %}, {% endif %}
{% endfor %}
)
{% endmacro %}3. Concretizing the Gold Model
Finally, the custom logic is bound to the target Gold layer model (e.g., gold_products.sql).
Note that while _change_type is captured within the {% else %} block to dictate compilation logic for the temporary engine, the target schema definition (dest_columns) filters out the operational field, leaving the final Gold model completely free of metadata.
{{ config(
materialized='incremental',
incremental_strategy='cdf_merge',
unique_key='code',
file_format='delta',
post_hook = [
"{{ set_cdf_version(this, source('silver_layer', 'products')) }}"
]
) }}
{% if not is_incremental() %}
-- Full refresh / Initial initialization bootstrap
SELECT code, name, unit, brand, category_id, category_name
FROM {{ source('silver_layer', 'products') }}
{% else %}
-- Incremental delta compilation via CDF
{% set last_v = get_cdf_version(this) %}
{% set silver_v_query %}
SELECT MAX(version)
FROM (DESCRIBE HISTORY {{ source('silver_layer', 'products') }})
{% endset %}
{% set current_silver_v = run_query(silver_v_query).columns[0][0] | int if execute %}
{% if execute and current_silver_v > last_v %}
{% set start_v = last_v + 1 %}
WITH raw_changes AS (
SELECT
code, name, unit, brand, category_id, category_name,
_change_type,
_commit_version,
ROW_NUMBER() OVER (PARTITION BY code ORDER BY _commit_version DESC) as latest_change
FROM table_changes('{{ source("silver_layer", "products") }}', {{ start_v }})
WHERE _change_type IN ('insert', 'update_postimage', 'delete')
)
SELECT
code, name, unit, brand, category_id, category_name,
_change_type
FROM raw_changes
WHERE latest_change = 1
{% else %}
-- Fallback loop to satisfy dbt compilation when no new logs exist
SELECT
code, name, unit, brand, category_id, category_name,
CAST(NULL AS STRING) as _change_type
FROM {{ this }}
WHERE 1=0
{% endif %}
{% endif %}Production Considerations & Operational Guardrails
When embedding custom incremental framework engines into enterprise data workflows, engineering teams should account for the following edge cases:
- Handling Empty Log Batches: If the upstream pipeline runs without changing the underlying data asset state, current_silver_v > last_v resolves to false. dbt still requires a valid, compilable query syntax block to construct internal execution graphs. The explicit WHERE 1=0 condition short-circuits execution times while providing the required metadata signature.
- Log Retention Limits & Data Compaction: This strategy depends entirely on the availability of the logs queried by table_changes(). It is vital to audit your Silver layer’s retention settings (delta.logRetentionDuration and delta.deletedFileRetentionDuration). If operational outages outlast log retention limits, the log sequence breaks, and the pipeline will throw an exception, requiring an explicit —full-refresh execution to resynchronize states.
Conclusion
By expanding the capabilities of dbt with a tailored incremental layout, our team successfully closed the feature gap between Delta Lake’s Change Data Feed log tracking and dbt’s model orchestrations. The resulting pipeline achieves highly efficient computational processing, processes upstream deletions atomically, and preserves the absolute clarity of our enterprise Gold layer definitions.
Matija Mijalković
Data Engineer, Eclept









Let’s build something great together!
30 min
Meet
“Every successful project starts with the right conversation. We’re here to listen, strategize, and find the best way forward, together.”
